Chapter 4 Bayesian regression models
We generally run experiments because we are interested in the relationship between two or more variables. A regression will tell us how our dependent variable, also called the response or outcome variable (e.g., pupil size, response times, accuracy, etc.) is affected by one or many independent variables, predictors, or explanatory variables. Predictors can be categorical (e.g., male or female), ordinal (first, second, third, etc.), or continuous (e.g., age). In this chapter we focus on simple regression models with different likelihood functions.
4.1 A first linear regression: Does attentional load affect pupil size?
Let us look at the effect of cognitive processing on human pupil size to illustrate the use of Bayesian linear regression models. Although pupil size is mostly related to the amount of light that reaches the retina or the distance to a perceived object, pupil sizes are also systematically influenced by cognitive processing: Increased cognitive load leads to an increase in the pupil size (for a review, see Mathot 2018).
For this example, we’ll use data from one subject’s pupil size of the control experiment by Wahn et al. (2016), averaged by trial. The data are available from df_pupil in the package bcogsci.
In this experiment, the subject covertly tracks between zero and five objects among several randomly moving objects on a computer screen. Viewing zero targets is called a passive viewing condition.
This task is called multiple object tracking (or MOT; see Pylyshyn and Storm 1988). First, several objects appear on the screen for two seconds, and a subset of the objects are indicated as “targets” at the beginning. Then, the objects start moving randomly across the screen and become indistinguishable. After several seconds, the objects stop moving and the subject need to indicate which objects were the targets. See Figure 4.1.17 Our research goal is to examine how the number of moving objects being tracked–that is, how attentional load–affects pupil size.
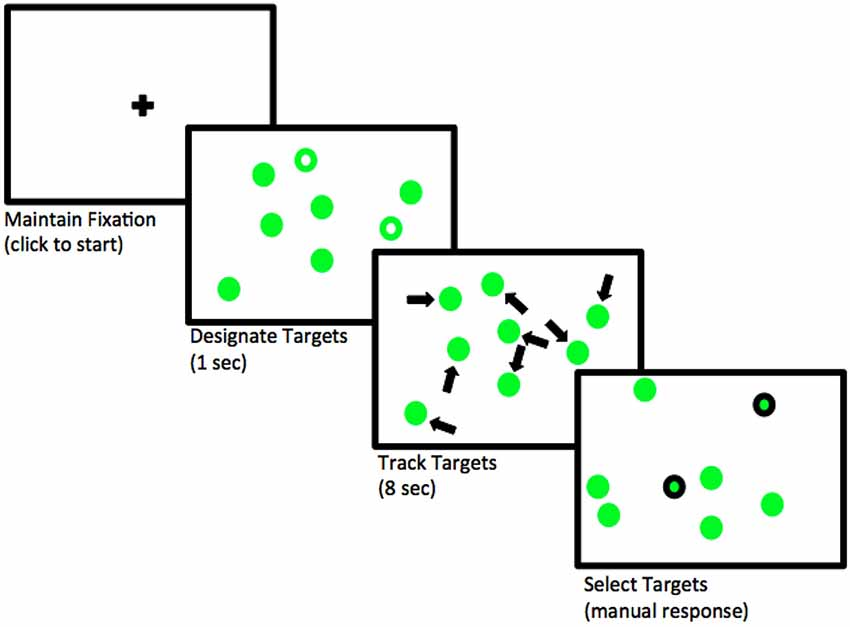
FIGURE 4.1: Flow of events in a trial where two objects need to be tracked. Adapted from Blumberg, Peterson, and Parasuraman (2015); licensed under CC BY 4.0 (https://creativecommons.org/licenses/by/4.0/).
4.1.1 Likelihood and priors
We will model pupil size as normally distributed, because we are not expecting a skew, and we have no further information available about the distribution of pupil sizes. (Given the units used here, pupil sizes cannot be of size zero or negative, so we know for sure that the choice of a normal likelihood is not exactly right.) For simplicity, assume a linear relationship between load and pupil size.
Let’s summarize our assumptions:
- There is some average pupil size, represented by \(\alpha\).
- The increase of attentional load has a linear relationship with pupil size, determined by \(\beta\).
- There is some noise in this process, that is, variability around the true pupil size. This variability is represented by the scale \(\sigma\).
- The noise is normally distributed.
The generative probability density function will be as follows:
\[\begin{equation} p\_size_n \sim \mathit{Normal}(\alpha + c\_load_n \cdot \beta,\sigma) \end{equation}\]
where \(n\) indicates the observation number with \(n = 1, \ldots, N\).
This means that the formula in brms will be p_size ~ 1 + c_load, where 1 represents the intercept, \(\alpha\), which doesn’t depend on the predictor, and c_load is the predictor that is multiplied by \(\beta\). The prefix c_ will generally indicate that a predictor (in this case load) is centered (i.e., the mean of all the values is subtracted from each value). If load is centered, the intercept represents the pupil size at the average load in the experiment (because at the average load, the centered load is zero, yielding \(\alpha + 0 \cdot \beta\)). If load had not been centered (i.e., starts with no load, then one, two, etc.), then the intercept would represent pupil size when there is no load. We could fit a frequentist model with lm(p_size ~ 1 + c_load, data_set); when we fit a Bayesian model using brms, the syntax is the same as in the lm() function, but we now have to specify priors for each of the parameters.
For setting plausible priors, some research needs to be done to find some information about pupil sizes. Although we might know that pupil diameters range between 2 to 4 mm in bright light to 4 to 8 mm in the dark (Spector 1990), this experiment was conducted with the Eyelink-II eyetracker which measures the pupils in arbitrary units (Hayes and Petrov 2016). If this is our first-ever analysis of pupil size, before setting up the priors, we’ll need to look at some measures of pupil size. (If we have analyzed this type of data before from previously conducted experiments, we could also look at estimates from those studies). Fortunately, we have some measurements of the same subject with no attentional load for the first 100 ms, measured every 10 ms, in the data frame df_pupil_pilot from the package bcogsci: This will give us some idea about the order of magnitude of our dependent variable.
data("df_pupil_pilot")
df_pupil_pilot$p_size %>% summary()## Min. 1st Qu. Median Mean 3rd Qu. Max.
## 852 856 862 861 866 868With this information we can set a regularizing prior for \(\alpha\). Center the prior around 1000 to be in the right order of magnitude.18 Since we don’t know how much pupil sizes are going to vary by load yet, we include a rather wide prior by defining it as a normal distribution and setting its standard deviation as \(500\).
\[\begin{equation} \alpha \sim \mathit{Normal}(1000, 500) \end{equation}\]
Given that our predictor load is centered, with the prior for \(\alpha\), we are saying that we suspect that the average pupil size for the average load in the experiment will be in a 95% credible interval limited by approximately \(1000 \pm 2 \cdot 500 = [0, 2000]\) units. We can calculate this with more precision in R using the qnorm() function:
qnorm(c(.025, .975), mean = 1000, sd = 500)## [1] 20 1980We know that the measurements of the pilot data are strongly correlated because they were taken 10 milliseconds apart. For this reason, they won’t give us a realistic estimate of how much the pupil size can vary. Accordingly, set up quite an uninformative prior for \(\sigma\) that encodes this lack of precise information: \(\sigma\) is surely larger than zero and has to be in the order of magnitude of the pupil size with no load.
\[\begin{equation} \sigma \sim \mathit{Normal}_+(0, 1000) \end{equation}\]
With this prior for \(\sigma\), we are saying that we expect that the standard deviation of the pupil sizes should be in the following 95% credible interval.
qtnorm(c(0.025, 0.975), mean = 0, sd = 1000, a = 0)## [1] 31.3 2241.4In order to compute the 95% credible interval, we used qtnorm() from the extraDistr package rather than qnorm(). As mentioned earlier, the relevant command specification is qtnorm(n, mean, sd, a = 0); recall that a = 0 indicates a truncated normal distribution, truncated at the left by zero.
The mean of \(\mathit{Normal}_+\), a normal distribution truncated at zero so as to allow for only positive values, does not coincide with its location indicated with the parameter \(\mu\) (and neither does the standard deviation coincide with the scale, \(\sigma\)); see online section A.2.
samples <- rtnorm(20000, mean = 0, sd = 1000, a = 0)
c(mean = mean(samples), sd = sd(samples))## mean sd
## 801 601We still need to set a prior for \(\beta\), the change in pupil size produced by the attentional load. Given that pupil size changes are not easily perceptible (we don’t usually observe changes in pupil size in our day-to-day life), we expect them to be much smaller than the pupil size (which we assume has mean 1000 units), so we use the following prior:
\[\begin{equation} \beta \sim \mathit{Normal}(0, 100) \end{equation}\]
With the prior of \(\beta\), we are saying that we don’t really know if increasing attentional load will increase or even decrease the pupil size (the prior distribution for \(\beta\) is centered at zero), but we do know that increasing one unit of load (that is, having one more object to track) will potentially change the pupil size in a way that is consistent with the following 95% credible interval.
qnorm(c(0.025, 0.975), mean = 0, sd = 100)## [1] -196 196That is, we don’t expect changes in size that increase or decrease the pupil size more than 200 units for one unit increase in load.
The priors we have specified here are relatively uninformative; as mentioned earlier, this is because we are considering the situation where we don’t have much prior experience with pupil size studies. In other settings, we might have more prior knowledge and experience; in that case, one could use somewhat more principled priors. We address this point in the online chapter on priors (online chapter E) and Bayesian workflow (online chapter F).
4.1.2 The brms model
Before fitting the brms model of the effect of load on pupil size, load the data and center the predictor load:
data("df_pupil")
(df_pupil <- df_pupil %>%
mutate(c_load = load - mean(load)))## # A tibble: 41 × 5
## subj trial load p_size c_load
## <int> <int> <int> <dbl> <dbl>
## 1 701 1 2 1021. -0.439
## 2 701 2 1 951. -1.44
## 3 701 3 5 1064. 2.56
## # ℹ 38 more rowsNow fit the brms model:
fit_pupil <-
brm(p_size ~ 1 + c_load,
data = df_pupil,
family = gaussian(),
prior = c(prior(normal(1000, 500), class = Intercept),
prior(normal(0, 1000), class = sigma),
prior(normal(0, 100), class = b, coef = c_load)))The only difference from our previous models is that we now have a predictor in the formula and in the priors. Priors for predictors are indicated with class = b, and the specific predictor with coef = c_load. If we want to set the same priors to different predictors we can omit the argument coef. Even if we drop the 1 from the formula, brm() will fit the same model as when we specify 1 explicitly. If we really want to remove the intercept, this must be indicated with 0 +... or -1 +.... Also see the online section A.3 for more details about the treatment of the intercept by brms. The priors are normal distributions for the intercept (\(\alpha\)) and the slope (\(\beta\)), and a truncated normal distribution for the scale parameter \(\sigma\), which coincides with the standard deviation (because the likelihood is a normal distribution). brms will automatically truncate the prior specification for \(\sigma\) and allow only positive values.
Next, inspect the output of the model. The posteriors and traceplots are shown in Figure 4.2; this figure is generated by typing:
plot(fit_pupil)
FIGURE 4.2: The posterior distributions of the parameters in the brms model fit_pupil, along with the corresponding traceplots.
fit_pupil## ...
## Population-Level Effects:
## Estimate Est.Error l-95% CI u-95% CI Rhat Bulk_ESS Tail_ESS
## Intercept 701.50 20.19 661.31 740.95 1.00 3552 2311
## c_load 33.76 12.12 9.80 57.46 1.00 3706 2712
##
## Family Specific Parameters:
## Estimate Est.Error l-95% CI u-95% CI Rhat Bulk_ESS Tail_ESS
## sigma 129.21 15.08 104.03 161.83 1.00 3287 2575
##
## ...In the next section, we discuss how one can communicate the relevant information from the model.
4.1.3 How to communicate the results?
We want to answer the research question “What is the effect of attentional load on the subject’s pupil size?” To answer this question, we’ll need to examine what happens with the posterior distribution of \(\beta\), which is printed out as c_load in the summary of brms. The summary of the posterior tells us that the most likely values of \(\beta\) will be around the mean of the posterior, 33.76, and we can be 95% certain that the value of \(\beta\), given the model and the data, lies between 9.8 and 57.46.
The model tells us that as attentional load increases, the pupil size of the subject becomes larger. If we want to determine the probability that the pupil size increases rather than decreases, we can compute the proportion of samples that lie above zero. (The intercept and the slopes are always preceded by b_ in brms. One can see all the names of parameters being estimated with variables().)
mean(as_draws_df(fit_pupil)$b_c_load > 0)## [1] 0.997This high probability does not mean that the effect of load is non-zero. It means instead that it’s much more probable that the effect is positive rather than negative. In order to claim that the effect is probably non-zero, we would have to compare the model with an alternative model in which the model assumes that the effect of load is assumed to be \(0\). We’ll come back to this issue when we discuss model comparison in chapter 12.
4.1.4 Descriptive adequacy
Our model converged and we obtained posterior distributions for the parameters. However, there is no guarantee that our model is good enough to represent our data. We can use posterior predictive checks to investigate the descriptive adequacy of the model.
Sometimes it’s useful to customize the posterior predictive check to visualize the fit of our model. We iterate over the different loads (e.g, 0 to 4), and we show the posterior predictive distributions based on 100 simulations for each load together with the observed pupil sizes in Figure 4.3. We don’t have enough data to derive a strong conclusion: both the predictive distributions and our data look very widely spread out, and it’s hard to tell if the distribution of the observations could have been generated by our model. For now we can say that it doesn’t look too bad.
for (l in 0:4) {
df_sub_pupil <- filter(df_pupil, load == l)
p <- pp_check(fit_pupil,
type = "dens_overlay",
ndraws = 100,
newdata = df_sub_pupil) +
geom_point(data = df_sub_pupil, aes(x = p_size, y = 0.0001)) +
ggtitle(paste("load: ", l)) +
coord_cartesian(xlim = c(400, 1000))
print(p)
}




FIGURE 4.3: The plot shows 100 posterior predicted distributions with the label \(y_{rep}\), the distribution of pupil size data in black with the label \(y\), and the observed pupil sizes in black dots for the five levels of attentional load.
In Figure 4.4, we look instead at the distribution of a summary statistic, such as mean pupil size by load. Figure 4.4 shows that the observed means for no load and for a load of one are falling in the tails of the distributions. Although our model predicts a monotonic increase of pupil size, the data might be indicating that the relevant difference is simply between no load, and some load. However, given the uncertainty in the posterior predictive distributions and that the observed means are contained somewhere in the predicted distributions, it could be the case that with this model we are overinterpreting noise.
for (l in 0:4) {
df_sub_pupil <- filter(df_pupil, load == l)
p <- pp_check(fit_pupil,
type = "stat",
ndraws = 1000,
newdata = df_sub_pupil,
stat = "mean") +
geom_point(data = df_sub_pupil, aes(x = p_size, y = 0.9)) +
ggtitle(paste("load: ", l)) +
coord_cartesian(xlim = c(400, 1000))
print(p)
}




FIGURE 4.4: Distribution of posterior predicted means in gray and observed pupil size means in black lines by load.
4.2 Log-normal model: Does trial affect response times?
Let us revisit the small experiment from section 3.2.1, where a subject repeatedly taps the space bar as fast as possible. Suppose that we want to know whether the subject tended to speed up (a practice effect) or slow down (a fatigue effect) while pressing the space bar. We’ll use the same data set df_spacebar as before, and we’ll center the column trial:
df_spacebar <- df_spacebar %>%
mutate(c_trial = trial - mean(trial))4.2.1 Likelihood and priors for the log-normal model
If we assume that finger-tapping times are log-normally distributed, the likelihood becomes:
\[\begin{equation} t_n \sim \mathit{LogNormal}(\alpha + c\_trial_n \cdot \beta,\sigma) \tag{4.1} \end{equation}\]
where \(n =1, \ldots, N\), and \(t\) is the dependent variable (finger tapping times in milliseconds). The variable \(N\) represents the total number of data points.
Use the same priors as in section 3.7.2 for \(\alpha\) (which is equivalent to \(\mu\) in the previous model) and for \(\sigma\).
\[\begin{equation} \begin{aligned} \alpha &\sim \mathit{Normal}(6, 1.5) \\ \sigma &\sim \mathit{Normal}_+(0, 1)\\ \end{aligned} \end{equation}\]
We still need a prior for \(\beta\). Effects are multiplicative rather than additive when we assume a log-normal likelihood, and that means that we need to take into account \(\alpha\) in order to interpret \(\beta\); for details, see online section A.4. We are going to try to understand how all our priors interact, by generating some prior predictive distributions. We start with the following prior centered in zero, a prior agnostic regarding the direction of the effect, which allows for a slowdown (\(\beta>0\)) and a speedup (\(\beta<0\)):
\[\begin{equation} \beta \sim \mathit{Normal}(0, 1) \end{equation}\]
Here is our first attempt at a prior predictive distribution:
# Ignore the dependent variable,
# use a vector of ones a placeholder.
df_spacebar_ref <- df_spacebar %>%
mutate(t = rep(1, n()))
fit_prior_press_trial <-
brm(t ~ 1 + c_trial,
data = df_spacebar_ref,
family = lognormal(),
prior = c(prior(normal(6, 1.5), class = Intercept),
prior(normal(0, 1), class = sigma),
prior(normal(0, 1), class = b, coef = c_trial)),
sample_prior = "only",
control = list(adapt_delta = .9))In order to understand the type of data that we are assuming a priori with the prior of the parameter \(\beta\), plot the median difference between the finger tapping times at adjacent trials. As the prior of \(\beta\) gets wider, larger differences are observed between adjacent trials. The objective of the prior predictive checks is to calibrate the prior of \(\beta\) to obtain a plausible range of differences.
We are going to plot a distribution of medians because they are less affected by the variance in the prior predicted distribution than the distribution of mean differences; distributions of means will have much more spread. To make the distribution of means more realistic, we would also need to find a more accurate prior for the scale \(\sigma\). (Recall that the mean of log-normal distributed values depend on both the location, \(\mu\) and the scale, \(\sigma\), of the distribution.) To plot the median effect, first define a function that calculates the difference between adjacent trials, and then apply the median to the result. We use that function in pp_check and show the result in Figure 4.5. As expected, the median effect is centered on zero (as is our prior), but we see that the distribution of possible medians for the effect is too widely spread out and includes values that are too extreme.
median_diff <- function(x) {
median(x - lag(x), na.rm = TRUE)
}
pp_check(fit_prior_press_trial,
type = "stat",
stat = "median_diff",
# show only prior predictive distributions
prefix = "ppd",
# each bin has a width of 500 ms
binwidth = 500) +
# cut the top of the plot to improve its scale
coord_cartesian(ylim = c(0, 50))
FIGURE 4.5: The prior predictive distribution of the median effect of the model defined in section 4.2 with \(\beta \sim \mathit{Normal}(0, 1)\).
Repeat the same procedure with \(\beta \sim \mathit{Normal}(0,0.01)\); the resulting prior predictive distribution is shown in Figure 4.6. The prior predictive distribution shows us that the prior is still quite vague; it is, however at least in the right order of magnitude.

FIGURE 4.6: The prior predictive distribution of the median difference in finger tapping times between adjacent trials based on the model defined in section 4.2 with \(\beta \sim \mathit{Normal}(0, 0.01)\).
Prior selection might look daunting and can be a lot of work. However, this work is usually done only the first time we start working with an experimental paradigm; besides, priors can be informed by the estimates from previous experiments (even maximum likelihood estimates from frequentist models can be useful). We will generally use very similar (or identical priors) for analyses dealing with the same type of task. When in doubt, a sensitivity analysis (see section 3.4) can tell us whether the posterior distribution depends unintentionally strongly on our prior selection. We also discuss prior selection in the online chapter E.
4.2.2 The brms model
We are now relatively satisfied with the priors for our model, and we can fit the model of the effect of trial on button-pressing time using brms. We need to specify that the family is lognormal().
fit_press_trial <-
brm(t ~ 1 + c_trial,
data = df_spacebar,
family = lognormal(),
prior = c(prior(normal(6, 1.5), class = Intercept),
prior(normal(0, 1), class = sigma),
prior(normal(0, 0.01), class = b, coef = c_trial)))Instead of printing out the complete output from the model, look at the estimates from the posteriors for the parameters \(\alpha\), \(\beta\), and \(\sigma\). These parameters are on the log scale:
posterior_summary(fit_press_trial,
variable = c("b_Intercept",
"b_c_trial",
"sigma"))## Estimate Est.Error Q2.5 Q97.5
## b_Intercept 5.118323 0.0064226 5.1054 5.130765
## b_c_trial 0.000524 0.0000637 0.0004 0.000649
## sigma 0.123262 0.0046246 0.1146 0.133082The posterior distributions can be plotted to obtain a graphical summary of all the parameters in the model (Figure 4.7):
plot(fit_press_trial)
FIGURE 4.7: Posterior distributions of the model of the effect of trial on button-pressing.
Next, we turn to the question of what we can report as our results, and what we can conclude from the data.
4.2.3 How to communicate the results?
As shown above, the first step is to summarize the posteriors in a table or graphically (or both). If the research relates to the effect estimated by the model, the posterior of \(\beta\) can be summarized in the following way: \(\hat\beta = 0.00052\), 95% CrI = \([ 0.0004 , 0.00065 ]\).
The effect is easier to interpret in milliseconds. We can transform the estimates back to the millisecond scale from the log scale, but we need to take into account that the scale is not linear, and that the effect between two button presses will differ depending on where we are in the experiment.
We will have a certain estimate if we consider the difference between response times in a trial at the middle of the experiment (when the centered trial number is zero) and the previous one (when the centered trial number is minus one).
alpha_samples <- as_draws_df(fit_press_trial)$b_Intercept
beta_samples <- as_draws_df(fit_press_trial)$b_c_trial
effect_middle_ms <- exp(alpha_samples) -
exp(alpha_samples - 1 * beta_samples)
## ms effect in the middle of the expt
## (mean trial vs. mean trial - 1)
c(mean = mean(effect_middle_ms),
quantile(effect_middle_ms, c(0.025, 0.975)))## mean 2.5% 97.5%
## 0.0875 0.0671 0.1083We will obtain a different estimate if we consider the difference between the second and the first trial:
first_trial <- min(df_spacebar$c_trial)
second_trial <- min(df_spacebar$c_trial) + 1
effect_beginning_ms <-
exp(alpha_samples + second_trial * beta_samples) -
exp(alpha_samples + first_trial * beta_samples)
## ms effect from first to second trial:
c(mean = mean(effect_beginning_ms),
quantile(effect_beginning_ms, c(0.025, 0.975)))## mean 2.5% 97.5%
## 0.0795 0.0623 0.0964So far; we converted the estimates to obtain median effects, that’s why we used \(exp(\cdot)\). If we want to obtain mean effects, we need to take into account \(\sigma\), since we need to calculate \(exp(\cdot + \sigma^2/2)\). However, we can also use the built-in function fitted() which calculates mean effects. Consider again the difference between the second and the first trial this time using fitted().
First, define for which observations we want to obtain the fitted values in millisecond scale. If we are interested in the difference between the second and first trial, create a data frame with their centered versions.
newdata_1 <- data.frame(c_trial = c(first_trial, second_trial))Second, use fitted() on the brms object, including the new data, and setting the summary parameter to FALSE. The first column contains the posterior samples transformed into milliseconds of the first trial, and the second column of the second trial.
beginning <- fitted(fit_press_trial,
newdata = newdata_1,
summary = FALSE)
head(beginning, 3)## [,1] [,2]
## [1,] 148 148
## [2,] 148 149
## [3,] 156 156The final step is to calculate the difference between trials, and report the mean and the 95% credible interval.
effect_beginning_ms <- beginning[, 2] - beginning[,1]
c(mean = mean(effect_beginning_ms),
quantile(effect_beginning_ms, c(0.025, 0.975)))## mean 2.5% 97.5%
## 0.0802 0.0628 0.0972Given that \(\sigma\) is much smaller than \(\mu\), \(\sigma\) doesn’t have a large influence on the mean effects, and the mean and 95% CrI of the mean and median effects are quite similar.
We see that no matter how we calculate the trial effect, there is a slowdown. When reporting the results of these analyses, one should present the posterior mean and a credible interval, and then reason about whether the observed estimates are consistent with the prediction from the theory being investigated. The 95% credible interval used here is just a convention adopted from standard practice in psychology and related areas, where the 95% confidence interval is the default. One could, for example, have used an 80% CrI.
The practical relevance of the effect for the research question can be important too. For example, only after \(100\) button presses do we see a barely noticeable slowdown:
effect_100 <-
exp(alpha_samples + 100 * beta_samples) -
exp(alpha_samples)
c(mean = mean(effect_100),
quantile(effect_100, c(0.025, 0.975)))## mean 2.5% 97.5%
## 8.99 6.85 11.19We need to consider whether our uncertainty of this estimate, and the estimated mean effect have any scientific relevance. Such relevance can be established by considering the previous literature, predictions from a quantitative model, or other expert domain knowledge. Sometimes, a quantitative meta-analysis is helpful; for examples, see Bürki, Alario, and Vasishth (2023), Cox et al. (2022), Bürki et al. (2020), Jäger, Engelmann, and Vasishth (2017), Mahowald et al. (2016), Nicenboim, Roettger, and Vasishth (2018), and Vasishth et al. (2013). We will discuss meta-analysis later in the book, in chapter 11.
Sometimes, researchers are only interested in establishing that an effect is present or absent; the magnitude and uncertainty of the estimate is of secondary interest. Here, the goal is to argue that there is evidence of a slowdown. The word evidence has a special meaning in statistics (Royall 1997), and in null hypothesis significance testing, a likelihood ratio test is the standard way to argue that one has evidence for an effect. In the Bayesian data analysis context, in order to answer such a question, a Bayes factor analysis must be carried out. We’ll come back to this issue in the model comparison chapters 12-14.
4.2.4 Descriptive adequacy
We look now at the predictions of the model. Since we now know that trial effects are very small, let’s examine the predictions of the model for differences in response times between 100 button presses. Similarly as for prior predictive checks, we define a function, median_diff100(), that calculates the median difference between a trial \(n\) and a trial \(n+100\). This time we’ll compare the observed median difference against the range of predicted differences based on the model and the data rather than only the model as we did for the prior predictions. Below we use virtually the same code that we use for plotting prior predictive checks, but since we now use the fitted model, we’ll obtain posterior predictive checks; this is displayed in Figure 4.8.
median_diff100 <- function(x) median(x - lag(x, 100), na.rm = TRUE)
pp_check(fit_press_trial,
type = "stat",
stat = "median_diff100")
FIGURE 4.8: The posterior predictive distribution of the median difference in response times between a trial \(n\) and a trial \(n+100\) based on the model fit_press_trial and the observed data.
From Figure 4.8, we can conclude that model predictions for differences in response trials between trials are reasonable.
4.3 Logistic regression: Does set size affect free recall?
In this section, we will learn how the principles we have learned so far can naturally extend to generalized linear models (GLMs). We focus on one special case of GLMs that has wide application in linguistics and psychology, logistic regression.
As an example data set, we look at a study investigating the capacity level of working memory. The data are a subset of a data set created by Oberauer (2019). Each subject was presented word lists of varying lengths (2, 4, 6, and 8 elements), and then was asked to recall a word given its position on the list; see Figure 4.9. We will focus on the data from one subject.
FIGURE 4.9: The flow of events in a trial with memory set size 4 and free recall. Adapted from Oberauer (2019); licensed under CC BY 4.0 (https://creativecommons.org/licenses/by/4.0/).
It is well-established that as the number of items to be held in working memory increases, performance, that is, accuracy, decreases (see Oberauer and Kliegl 2001, among others). We will investigate this claim with data from only one subject.
The data can be found in df_recall in the package bcogsci. The code below loads the data, centers the predictor set_size, and briefly explores the data set.
data("df_recall")
df_recall <- df_recall %>%
mutate(c_set_size = set_size - mean(set_size))
# Set sizes in the data set:
df_recall$set_size %>%
unique() %>% sort()## [1] 2 4 6 8# Trials by set size
df_recall %>%
group_by(set_size) %>%
count()## # A tibble: 4 × 2
## # Groups: set_size [4]
## set_size n
## <int> <int>
## 1 2 23
## 2 4 23
## 3 6 23
## # ℹ 1 more rowHere, the column correct records the incorrect vs. correct responses with 0 vs 1 respectively, and the column c_set_size records the centered memory set size; these latter scores have continuous values -3, -1, 1, and 3. These continuous values are centered versions of 2, 4, 6, and 8.
df_recall## # A tibble: 92 × 8
## subj set_size correct trial session block tested c_set_size
## <chr> <int> <int> <int> <int> <int> <int> <dbl>
## 1 10 4 1 1 1 1 2 -1
## 2 10 8 0 4 1 1 8 3
## 3 10 2 1 9 1 1 2 -3
## # ℹ 89 more rowsWe want to model the trial-by-trial accuracy and examine whether the probability of recalling a word is related to the number of words in the set that the subject needs to remember.
4.3.1 The likelihood for the logistic regression model
Recall that the Bernoulli likelihood generates a \(0\) or \(1\) response with a particular probability \(\theta\). For example, one can generate simulated data for \(10\) observations, with a \(50\)% probability of getting a \(1\) using rbern() from the package extraDistr.
rbern(10, prob = 0.5)## [1] 0 0 0 1 1 0 0 0 1 0We can therefore define each dependent value correct_n in the data as being generated from a Bernoulli random variable with probability of success \(\theta_n\).
Here, \(n = 1, \ldots, N\) indexes the observation, \(correct_n\) is the dependent variable (\(0\) indicates an incorrect recall and \(1\) a correct recall), and \(\theta_n\) is the probability of correctly recalling a probe in a given observation \(n\).
\[\begin{equation} correct_n \sim \mathit{Bernoulli}(\theta_n) \tag{4.2} \end{equation}\]
Since the observed data are either \(0\) or \(1\), we shouldn’t just fit a regression model using the normal (or log-normal) likelihood as we did in the preceding examples. Such a model would be inappropriate because it would assume that the observed data are real numbers ranging from \(-\infty\) to \(+\infty\) (or from \(0\) to \(+\infty\)).
The generalized linear modeling framework solves this problem by defining a link function \(g(\cdot)\) that connects the linear model to the quantity to be estimated (here, the probabilities \(\theta_n\)). The link function used for \(0\), \(1\) responses is called the logit link, and is defined as follows.
\[\begin{equation} \eta_n = g(\theta_n) = \log\left(\frac{\theta_n}{1-\theta_n}\right) \end{equation}\]
The term $} \(\frac{\theta_n}{1-\theta_n}\) is called the odds.19 The logit link function is therefore a log-odds; it maps probability values ranging from \((0,1)\) to real numbers lying between \(-\infty\) and \(+\infty\). Figure 4.10 shows the logit link function, \(\eta = g(\theta)\), and the inverse logit, \(\theta = g^{-1}(\eta)\), which is called the logistic function; the relevance of this logistic function will become clear in a moment.

FIGURE 4.10: The logit and inverse logit (logistic) function.
The linear model is now fit not to the \(0\),\(1\) responses as the dependent variable, but to \(\eta_n\), i.e., log-odds, as the dependent variable:
\[\begin{equation} \eta_n = \log\left(\frac{\theta_n}{1-\theta_n}\right) = \alpha + \beta \cdot c\_set\_size \end{equation}\]
Unlike linear models, the model is defined so that there is no residual error term (\(\varepsilon\)) in this model. Once \(\eta_n\) is estimated, one can solve the above equation for \(\theta_n\) (in other words, we compute the inverse of the logit function and obtain the estimates on the probability scale). This gives the above-mentioned logistic regression function:
\[\begin{equation} \theta_n = g^{-1}(\eta_n) = \frac{\exp(\eta_n)}{1+\exp(\eta_n)} = \frac{1}{1+exp(-\eta_n)} \end{equation}\]
The last equality in the equation above arises by dividing both the numerator and denominator by \(\exp(\eta_n)\).
In summary, the generalized linear model with the logit link fits the following Bernoulli likelihood:
\[\begin{equation} correct_n \sim \mathit{Bernoulli}(\theta_n) \tag{4.3} \end{equation}\]
The model is fit on the log-odds scale, \(\eta_n = \alpha + c\_set\_size_n \cdot \beta\). Once \(\eta_n\) has been estimated, the inverse logit or the logistic function is used to compute the probability estimates \(\theta_n = \frac{\exp(\eta_n)}{1+\exp(\eta_n)}\). An example of this calculation will be shown in the next section.
4.3.2 Priors for the logistic regression
In order to decide on priors for \(\alpha\) and \(\beta\), we need to take into account that these parameters do not represent probabilities or proportions, but log-odds, the x-axis in Figure 4.10 (right-hand side figure). As shown in the figure, the relationship between log-odds and probabilities is not linear.
There are two functions in R that implement the logit and inverse logit functions: qlogis(p) for the logit function and plogis(x) for the inverse logit or logistic function.
Now we need to set priors for \(\alpha\) and \(\beta\). Given that we centered our predictor, the intercept, \(\alpha\), represents the log-odds of correctly recalling one word in a random position for the average set size of five (since \(5 = \frac{2+4+6+8}{4}\)), which, incidentally, was not presented in the experiment. This is one case where the intercept doesn’t have a clear interpretation if we leave the prediction uncentered: With non-centered set size, the intercept will be the log-odds of recalling one word in a set of zero words, which obviously makes no sense.
The prior for \(\alpha\) will depend on how difficult the recall task is. We could assume that the probability of recalling a word for an average set size, \(\alpha\), is centered at \(0.5\) (a \(50/50\) chance) with a great deal of uncertainty. The R command qlogis(0.5) tells us that \(0.5\) corresponds to zero in log-odds space. How do we include a great deal of uncertainty? We could look at Figure 4.10, and decide on a standard deviation of \(4\) in a normal distribution centered at zero:
\[\begin{equation} \alpha \sim \mathit{Normal}(0, 4) \end{equation}\]
Let’s plot this prior in log-odds and in probability scale by drawing random samples.
samples_log_odds <- tibble(log_odds = rnorm(100000, 0, 4))
samples_p <- tibble(p = plogis(rnorm(100000, 0, 4)))
ggplot(samples_log_odds, aes(log_odds)) +
geom_density()
ggplot(samples_p, aes(p)) +
geom_density()

FIGURE 4.11: The prior for \(\alpha \sim \mathit{Normal}(0, 4)\) in log-odds and in probability space.
Figure 4.11 shows that our prior assigns more probability mass to extreme probabilities of recall than to intermediate values. Clearly, this is not what we intended.
We could try several values for the standard deviation of the prior until we find a prior that make sense for us. Reducing the standard deviation to 1.5 seems to make sense as shown in Figure 4.12.
\[\begin{equation} \alpha \sim \mathit{Normal}(0, 1.5) \end{equation}\]


FIGURE 4.12: Prior for \(\alpha \sim \mathit{Normal}(0, 1.5)\) in log-odds and in probability space.
We need to decide now on the prior for \(\beta\), the effect in log-odds of increasing the set size. We could choose a normal distribution centered on zero, reflecting our lack of any commitment regarding the direction of the effect. Let’s get some intuitions regarding different possible standard deviations for this prior, by testing the following distributions as priors:
- \(\beta \sim \mathit{Normal}(0, 1)\)
- \(\beta \sim \mathit{Normal}(0, .5)\)
- \(\beta \sim \mathit{Normal}(0, .1)\)
- \(\beta \sim \mathit{Normal}(0, .01)\)
- \(\beta \sim \mathit{Normal}(0, .001)\)
In principle, we could produce the prior predictive distributions using brms with sample_prior = "only" and then predict(). However, as mentioned before, brms also uses Stan’s Hamiltonian sampler for sampling from the priors, and this can lead to convergence problems when the priors are too uninformative (as in this case). We solve this issue by performing prior predictive checks directly in R using the r* family of functions (e.g., rnorm(), rbinom(), etc.) together with loops. This method is not as simple as using the convenient functions provided by brms, but it is very flexible and can be very powerful. We show the prior predictive distributions in Figure 4.13; for the details on the implementation in R, see online section A.5.
Figure 4.13 shows that, as expected, the priors are centered on zero. We see that the distribution of possible accuracies for the prior that has a standard deviation of \(1\) is problematic: There is too much probability concentrated near \(0\) and \(1\) for set sizes of \(2\) and \(8\). It’s hard to tell the differences between the other priors, and it might be more useful to look at the predicted differences in accuracy between set sizes in Figure 4.14.

FIGURE 4.13: The prior predictive distributions of mean accuracy of the model defined in section 4.3, for different set sizes and different priors for \(\beta\).

FIGURE 4.14: The prior predictive distributions of differences in mean accuracy between set sizes of the model defined in section 4.3 for different priors for \(\beta\).
If we are not sure whether the increase of set size could produce something between a null effect and a relatively large effect, we can choose the prior with a standard deviation of \(0.1\). Under this reasoning, we settle on the following priors:
\[\begin{equation} \begin{aligned} \alpha &\sim \mathit{Normal}(0, 1.5) \\ \beta &\sim \mathit{Normal}(0, 0.1) \end{aligned} \end{equation}\]
4.3.3 The brms model
Having decided on the likelihood, the link function, and the priors, the model can now be fit using brms. We need to specify that the family is bernoulli(), and the link is logit.
fit_recall <-
brm(correct ~ 1 + c_set_size,
data = df_recall,
family = bernoulli(link = logit),
prior = c(prior(normal(0, 1.5), class = Intercept),
prior(normal(0, 0.1), class = b, coef = c_set_size)))Next, look at the summary of the posteriors of each of the parameters. Keep in mind that the parameters are in log-odds space:
posterior_summary(fit_recall,
variable = c("b_Intercept", "b_c_set_size"))## Estimate Est.Error Q2.5 Q97.5
## b_Intercept 1.919 0.3165 1.332 2.5856
## b_c_set_size -0.182 0.0805 -0.344 -0.0297Inspecting b_c_set_size, we see that increasing the set size has a detrimental effect on recall, as we suspected.
Plot the posteriors as well (Figure 4.15):
plot(fit_recall)
FIGURE 4.15: The posterior distributions of the parameters in the brms model fit_recall, along with the corresponding traceplots.
Next, we turn to the question of what we can report as our results, and what we can conclude from the data.
4.3.4 How to communicate the results?
Here, we are in a situation analogous to the one we saw earlier with the log-normal model. If we want to talk about the effect estimated by the model in log-odds space, we summarize the posterior of \(\beta\) in the following way: \(\hat\beta = -0.182\), 95% CrI = \([ -0.344 , -0.03 ]\).
However, the effect is easier to understand in proportions rather than in log-odds. Let’s look at the average accuracy for the task first:
alpha_samples <- as_draws_df(fit_recall)$b_Intercept
av_accuracy <- plogis(alpha_samples)
c(mean = mean(av_accuracy), quantile(av_accuracy, c(0.025, 0.975)))## mean 2.5% 97.5%
## 0.868 0.791 0.930As before, to transform the effect of our manipulation to an easier to interpret scale (i.e., proportions), we need to take into account that the scale is not linear, and that the effect of increasing the set size depends on the average accuracy, and the set size that we start from.
We can do the following calculation, similar to what we did for the trial effects experiment, to find out the decrease in accuracy in proportions or probability scale:
beta_samples <- as_draws_df(fit_recall)$b_c_set_size
effect_middle <- plogis(alpha_samples) -
plogis(alpha_samples - beta_samples)
c(mean = mean(effect_middle),
quantile(effect_middle, c(0.025, 0.975)))## mean 2.5% 97.5%
## -0.01871 -0.03580 -0.00319Notice the interpretation here, if we increase the set size from the average set size minus one to the average set size, we get a reduction in the accuracy of recall of \(-0.019\), 95% CrI = \([ -0.036 , -0.003 ]\). Recall that the average set size, 5, was not presented to the subject! We could alternatively look at the decrease in accuracy from a set size of \(2\) to \(4\):
four <- 4 - mean(df_recall$set_size)
two <- 2 - mean(df_recall$set_size)
effect_4m2 <-
plogis(alpha_samples + four * beta_samples) -
plogis(alpha_samples + two * beta_samples)
c(mean = mean(effect_4m2),
quantile(effect_4m2, c(0.025, 0.975)))## mean 2.5% 97.5%
## -0.02935 -0.05241 -0.00615We can also back-transform to probability scale using the function fitted() rather than using plogis(). One advantage is that this will work regardless of the type of link function; in this section we only discussed the logit link, but other link functions are possible to use in generalized linear models (e.g., the probit link; see Dobson and Barnett 2011).
Since set size is the only predictor and it is centered, for estimating the average accuracy, we can consider an imaginary observation where the c_set_size is zero, which corresponds to an average set size. (If there were more centered predictors, we would need to set all of them to zero). Now we can use the summary argument provided by fitted().
fitted(fit_recall,
newdata = data.frame(c_set_size = 0),
summary = TRUE)[,c("Estimate", "Q2.5","Q97.5")]## Estimate Q2.5 Q97.5
## 0.868 0.791 0.930For estimating the difference in accuracy from the average set size minus one to the average set size, and from a set size of two to four, first, define newdata with these set sizes.
new_sets <- data.frame(c_set_size = c(0, -1, four, two))
set_sizes <- fitted(fit_recall,
newdata = new_sets,
summary = FALSE)Then calculate the appropriate differences considering that column one of set_sizes corresponds to the average set size, column two to the average set size minus one, and so forth.
effect_middle <- set_sizes[, 1] - set_sizes[, 2]
effect_4m2 <- set_sizes[, 3] - set_sizes[, 4] Finally, calculate the summaries.
c(mean = mean(effect_middle), quantile(effect_middle,
c(0.025, 0.975)))## mean 2.5% 97.5%
## -0.01871 -0.03580 -0.00319c(mean = mean(effect_4m2), quantile(effect_4m2,
c(0.025, 0.975)))## mean 2.5% 97.5%
## -0.02935 -0.05241 -0.00615As expected, we get exactly the same values with fitted() as when we calculate them “by hand.”
4.3.5 Descriptive adequacy
One potentially useful aspect of posterior distributions is that we could also make predictions for other conditions not presented in the actual experiment, such as set sizes that weren’t tested. We could then carry out another experiment to investigate whether our model was right using another experiment. To make predictions for other set sizes, we extend our data set, adding rows with set sizes of \(3\), \(5\), and \(7\). To be consistent with the data of the other set sizes in the experiment, we add \(23\) observations for each new set size (this is the number of observations by set size in the data set). Something important to notice is that we need to center our predictor based on the original mean set size. This is because we want to maintain our interpretation of the intercept. We extend the data as follows, and we summarize the data and plot it in Figure 4.16.
df_recall_ext <- df_recall %>%
bind_rows(tibble(set_size = rep(c(3, 5, 7), 23),
c_set_size = set_size -
mean(df_recall$set_size),
correct = 0))
# nicer label for the facets:
set_size <- paste("set size", 2:8) %>%
setNames(-3:3)
pp_check(fit_recall,
type = "stat_grouped",
stat = "mean",
group = "c_set_size",
newdata = df_recall_ext,
facet_args = list(ncol = 1, scales = "fixed",
labeller = as_labeller(set_size)),
binwidth = 0.02)
FIGURE 4.16: The distributions of posterior predicted mean accuracies for tested set sizes (2, 4, 6, and 8) and untested ones (3, 5, and 7) are labeled with \(y_{rep}\). The observed mean accuracy, \(y\), are only relevant for the tested set sizes 2, 4, 6, and 8); the “observed” accuracies of the untested set sizes are represented as 0.
We could now gather new data in an experiment that also shows set sizes of \(3\), \(5\), and \(7\). These data would be held out from the model fit_recall, since the model was fit when those data were not available. Verifying that the new observations fit in our already generated posterior predictive distribution would be a way to test genuine predictions from our model.
Having seen how we can fit simple regression models, we turn to hierarchical models in the next chapter.
4.4 Summary
In this chapter, we learned how to fit simple linear regression models and to fit and interpret models with a log-normal likelihood and logistic regression models. We investigated the prior specification for the models, using prior predictive checks, and the descriptive adequacy of the models using posterior predictive checks.
4.5 Further reading
Linear regression is discussed in several classic textbooks; these have largely a frequentist orientation, but the basic theory of linear modeling presented there can easily be extended to the Bayesian framework. An accessible textbook is by Dobson and Barnett (2011). Other useful textbooks on linear modeling are Harrell Jr. (2015), Faraway (2016), Fox (2015), and Montgomery, Peck, and Vining (2012).
References
Blumberg, Eric J., Matthew S. Peterson, and Raja Parasuraman. 2015. “Enhancing Multiple Object Tracking Performance with Noninvasive Brain Stimulation: A Causal Role for the Anterior Intraparietal Sulcus.” Frontiers in Systems Neuroscience 9: 3. https://doi.org/10.3389/fnsys.2015.00003.
Bürki, Audrey, Francois-Xavier Alario, and Shravan Vasishth. 2023. “When Words Collide: Bayesian Meta-Analyses of Distractor and Target Properties in the Picture-Word Interference Paradigm.” Quarterly Journal of Experimental Psychology 76 (6): 1410–30. https://doi.org/https://doi.org/10.1177/17470218221114644.
Bürki, Audrey, Shereen Elbuy, Sylvain Madec, and Shravan Vasishth. 2020. “What Did We Learn from Forty Years of Research on Semantic Interference? A Bayesian Meta-Analysis.” Journal of Memory and Language 114. https://doi.org/10.1016/j.jml.2020.104125.
Cox, Christopher Martin Mikkelsen, Tamar Keren-Portnoy, Andreas Roepstorff, and Riccardo Fusaroli. 2022. “A Bayesian Meta-Analysis of Infants’ Ability to Perceive Audio–Visual Congruence for Speech.” Infancy 27 (1): 67–96.
Dobson, Annette J., and Adrian Barnett. 2011. An Introduction to Generalized Linear Models. CRC Press.
Faraway, Julian James. 2016. Extending the Linear Model with R: Generalized Linear, Mixed Effects and Nonparametric Regression Models. Chapman; Hall/CRC.
Fox, John. 2015. Applied Regression Analysis and Generalized Linear Models. Sage Publications.
Harrell Jr., Frank E. 2015. Regression Modeling Strategies: With Applications to Linear Models, Logistic and Ordinal Regression, and Survival Analysis. New York, NY: Springer.
Hayes, Taylor R., and Alexander A. Petrov. 2016. “Mapping and Correcting the Influence of Gaze Position on Pupil Size Measurements.” Behavior Research Methods 48 (2): 510–27. https://doi.org/10.3758/s13428-015-0588-x.
Jäger, Lena A., Felix Engelmann, and Shravan Vasishth. 2017. “Similarity-Based Interference in Sentence Comprehension: Literature review and Bayesian meta-analysis.” Journal of Memory and Language 94: 316–39. https://doi.org/https://doi.org/10.1016/j.jml.2017.01.004.
Mahowald, Kyle, Ariel James, Richard Futrell, and Edward Gibson. 2016. “A Meta-Analysis of Syntactic Priming in Language Production.” Journal of Memory and Language 91: 5–27. https://doi.org/https://doi.org/10.1016/j.jml.2016.03.009.
Mathot, Sebastiaan. 2018. “Pupillometry: Psychology, Physiology, and Function.” Journal of Cognition 1 (1): 16. https://doi.org/10.5334/joc.18.
Montgomery, D. C., E. A. Peck, and G. G. Vining. 2012. An Introduction to Linear Regression Analysis. 5th ed. Hoboken, NJ: Wiley.
Nicenboim, Bruno, Timo B. Roettger, and Shravan Vasishth. 2018. “Using Meta-Analysis for Evidence Synthesis: The case of incomplete neutralization in German.” Journal of Phonetics 70: 39–55. https://doi.org/https://doi.org/10.1016/j.wocn.2018.06.001.
Oberauer, Klaus. 2019. “Working Memory Capacity Limits Memory for Bindings.” Journal of Cognition 2 (1): 40. https://doi.org/10.5334/joc.86.
Oberauer, Klaus, and Reinhold Kliegl. 2001. “Beyond Resources: Formal Models of Complexity Effects and Age Differences in Working Memory.” European Journal of Cognitive Psychology 13 (1-2): 187–215. https://doi.org/10.1080/09541440042000278.
Pylyshyn, Zenon W., and Ron W. Storm. 1988. “Tracking Multiple Independent Targets: Evidence for a Parallel Tracking Mechanism.” Spatial Vision 3 (3): 179–97. https://doi.org/10.1163/156856888X00122.
Royall, Richard. 1997. Statistical Evidence: A Likelihood Paradigm. New York: Chapman; Hall, CRC Press.
Spector, Robert H. 1990. “The Pupils.” In Clinical Methods: The History, Physical, and Laboratory Examinations, edited by H. Kenneth Walker, W. Dallas Hall, and J. Willis Hurst, 3rd ed. Boston: Butterworths.
Vasishth, Shravan, Zhong Chen, Qiang Li, and Gueilan Guo. 2013. “Processing Chinese Relative Clauses: Evidence for the Subject-Relative Advantage.” PLoS ONE 8 (10): 1–14. https://doi.org/https://doi.org/10.1371/journal.pone.0077006.
Wahn, Basil, Daniel P. Ferris, W. David Hairston, and Peter König. 2016. “Pupil Sizes Scale with Attentional Load and Task Experience in a Multiple Object Tracking Task.” PLOS ONE 11 (12): e0168087. https://doi.org/10.1371/journal.pone.0168087.
The description of the procedure in the Wahn et al. (2016) paper is as follows: “At the beginning of a trial, all objects were shown for two seconds. Then, a subset of objects turned gray for two seconds, indicating the targets and then reverted back to look like all the other objects. After an additional 500 ms, objects started to move and participants were instructed to track the targets. While objects were moving, they repelled each other and bounced off the screen borders.”↩︎
The average pupil size will probably be higher than 800, since this measurement was with no load, but, in any case, the exact number won’t matter, any mean for the prior between 500-1500 would be fine if the standard deviation is large.↩︎
Odds are defined to be the ratio of the probability of success to the probability of failure. For example, the odds of obtaining a one in a fair six-sided die are \(\frac{1/6}{1-1/6}=1/5\). The odds of obtaining a heads in a fair coin are \(1/1\). Do not confuse this technical term with the day-to-day usage of the word “odds” to mean probability.↩︎